First let's talk discuss what a Graph Database is, then we’ll talk about how we can use a Graph Database to create a GraphRag solution
What is GraphRag and when would we need it?
I assume you know what RAG is: Retrieval Augmented Generation. The RAG concept is that we go into our databases or document stores and pull out the grounding data that’s most relevant to a user input, add the retrieved content to the LLM prompt, and the LLM can use the grounding data to help generate a more informed answer to the prompt.

There are two common two RAG approaches most of us are probably familiar with:
- Storing vectors used for concept similarly search —very common for answering factual questions about *PDF documents for example
- Direct database queries — for example answering questions about recent orders placed by a customer when the data is stored in an ERP system or a data warehouse.
These techniques work great, but are less effective when relationships between data entities is very important. Think about an LLM that needs to answer questions like:
"Which physicians performed which procedures for which patients in which facilities"
or
"What current contracts for network equipment have NET30 terms?"
These types of questions are usually difficult to answer with either similarity search or relational database queries.

When the questions are which data entities had which actions or have what relationship to other data entities—graph data storage is at the top of the list.
Notable Graph Databases
There are a few notable Graph Database technologies we can leverage for Graph data storage, for example Neo4J, ArangoDB, and Amazon Neptune. Graph Databases have been around for a while, and have many uses in addition to AI GraphRag solutions.
This leads us to GraphRAG
GraphRAG does what it sounds like — it enables us to surface data within a graph database to an LLM for use as prompt grounding data.
We use GraphRag similar to how we use relational databases with RAG — query a Graph database for facts that answer a user’s questions, and provide it to the prompt.
A business example might be extracting key facts from purchase contracts, and then storing them in a Graph database so the relationships between contracts and terms is easily queried.
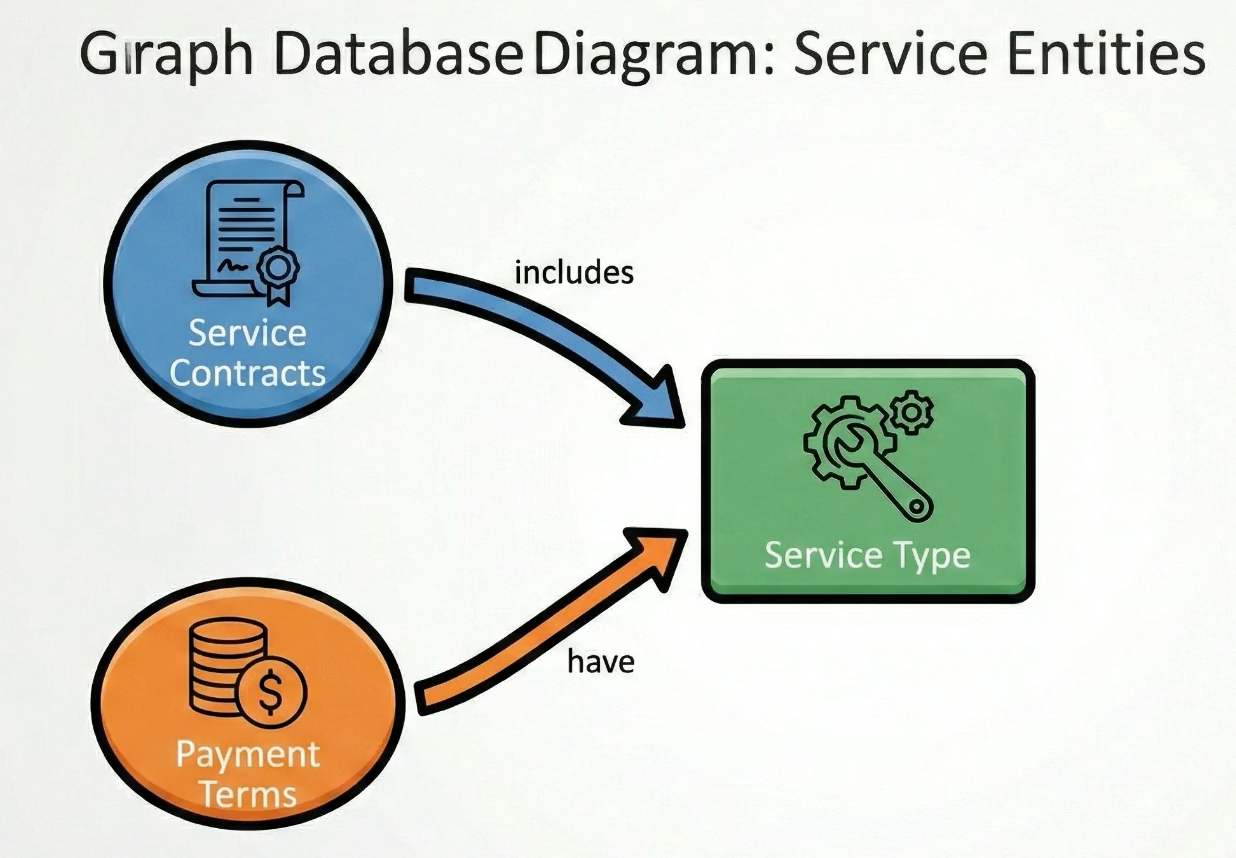
Think about a user asking how many service contracts have best price guarantees and cover professional services. If our graph database stored “contract” and “professional services” as entities and and “best price guarantee” as a contract attribute, we could easily pull a list of contracts where the subject area list includes “professional services” and the “Best price guarantee” property is true.
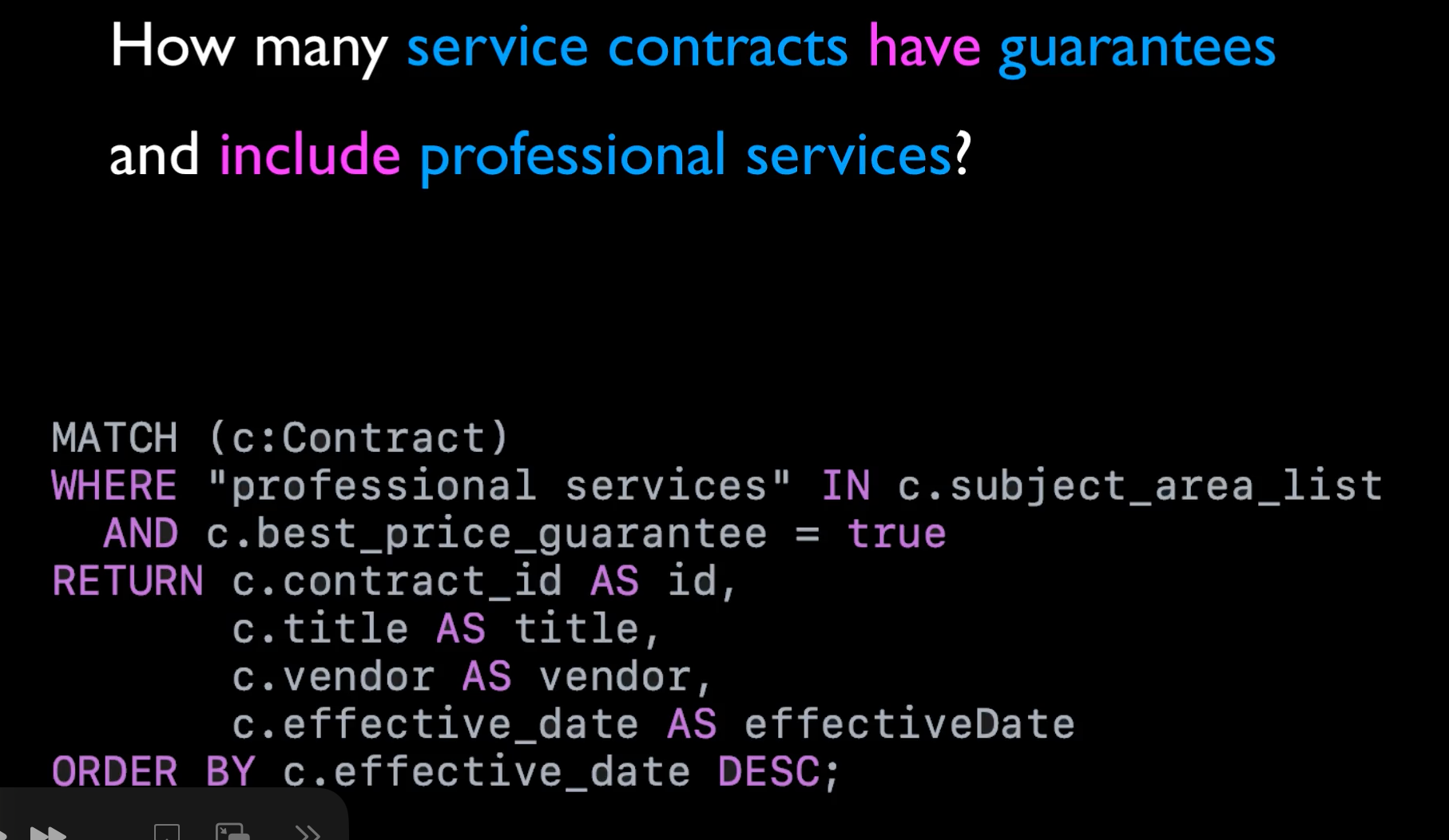
We can combine GraphRAG and other RAG approaches. For example, maybe we have questions about contracts that meet all the criteria mentioned before– we could use GraphRag to get the set of contacts that meet the filter criteria, then use a vector similarity search only including that specific set of contracts—leading to a more accurate response.
OK now we’re on the same page in the concepts, let’s put this into practice.
Let's See This in Action
To keep things light and fun, for this video we’ll build a GraphRag AI solution that can answer questions about movies, directors, actors, and genres. We’ll call the app “Cinegraph”
I’ll be using this sample data file of 100 movies. It’s a CSV file, and There are actually some one-to-many relationships in here—for example a movie can have multiple actors and genres. We’ll capture those relationships when we load the data into the graph database.
The graph database will index along these known entities:
- Movie, Production Company, Person, and Genre
Movies have relationships to people. Those relationships can be:
- DIRECTED
- WROTE
- ACTED IN
Movies have relationships to Genres
- HAS_GENRE
Movies also have relationships to Production companies
- PRODUCED_BY
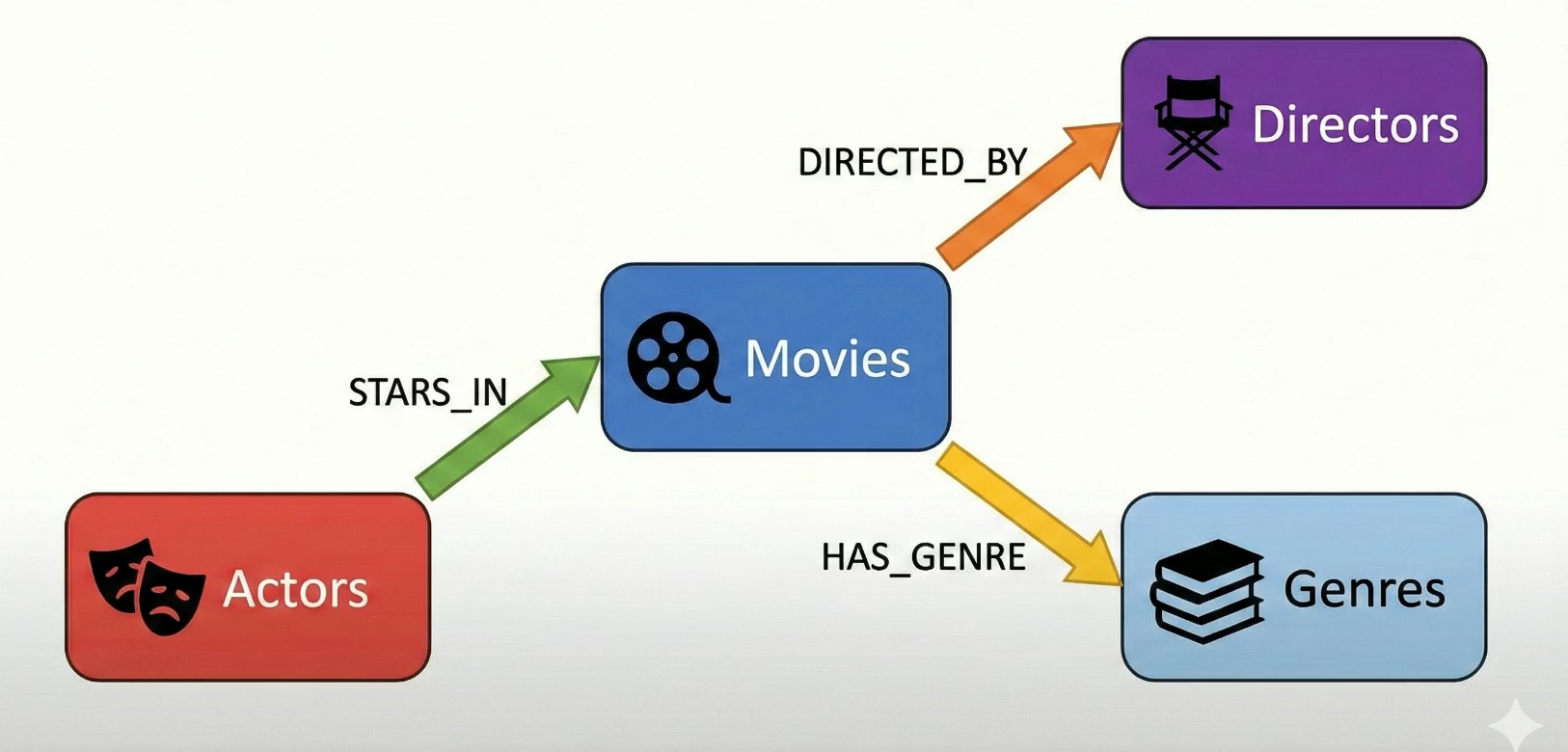
As we import the CSV file, we’ll add all these entities (Movie, Company, Person, Genre) as Entities, and store the relationships between them.
As we dig into the code, it’ll become apparent why the graph database—being purpose-built to model these relationships—is both easier to use and more performant than a many-to-many relational database approach.
Deployed Architecture
Here’s the deployed architecture for this solution. In my lab, the entire solution is deployed as four containers in a docker compose stack. You could adapt the code to your own architecture, and host some or all of it in the cloud if you prefer.
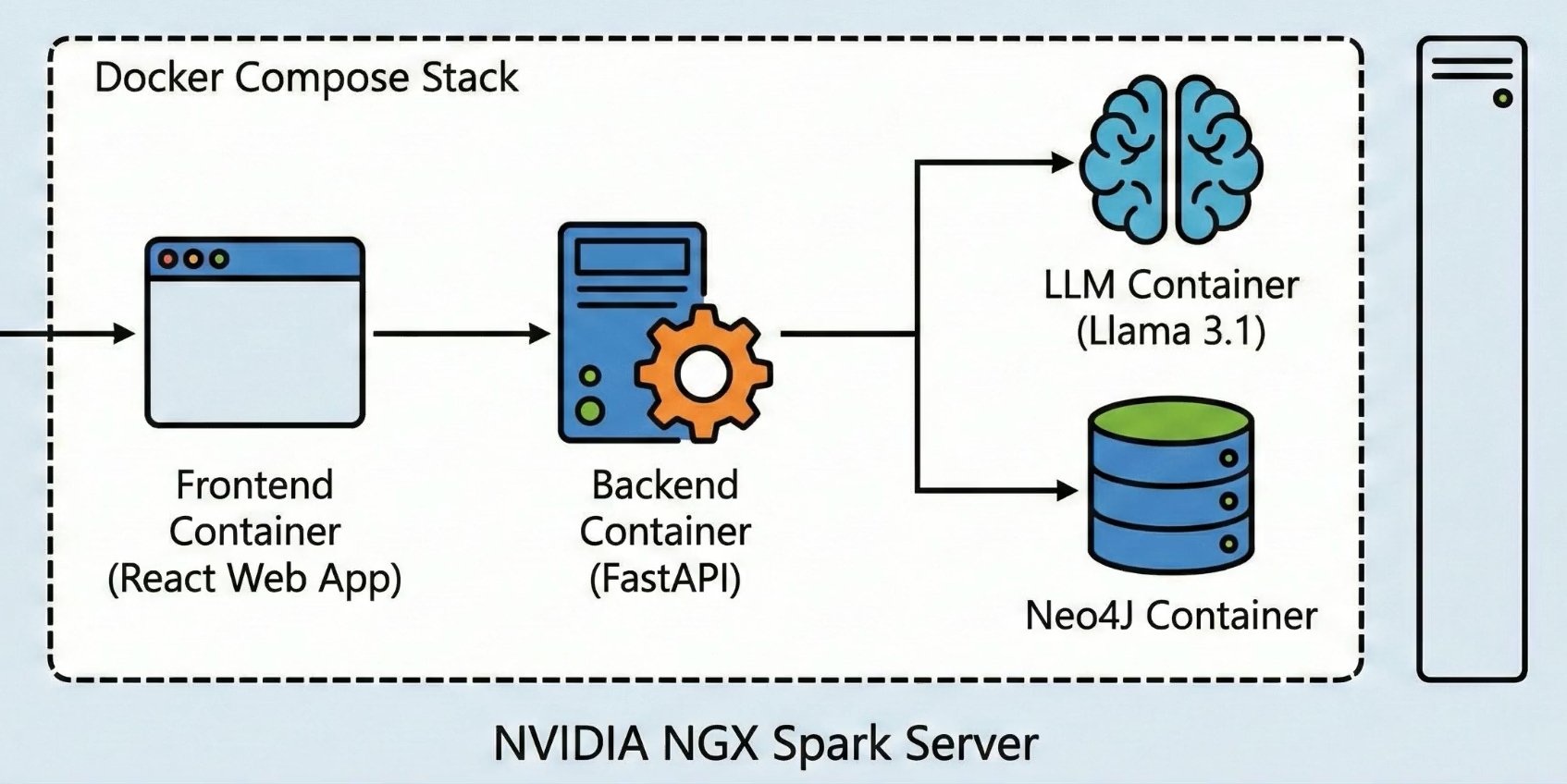
LLM Service
First - we have the LLM deployed in a container. We’ll using the LLM to analyze user questions to determine which entities and relationships they’re asking about, and also to generate a text response that incorporates the GraphRAG grounding data. We’ve deployed this as a local Llama 3.1-8B Instruct model in FP8 quantization.
Graph Database Service
Second - we have Neo4J deployed in a container. This will run the Graph Database for us.
Frontend and Backend Services
Next are the backend and frontend services.
- The backend is a FastAPI REST service that leverages the Llama LLM and Neo4J to answer user questions, while the front end is a Next.js web app that has a single chatbot page.
- The user uses the React app to ask a question about directors, movies or actors in natural language.
- The backend uses the LLM to break down the question to match what the user said into entities and graph relationships.
- Then the backend queries the Graph to get the grounding data.
- Finally the backend sends the original question and grounding data to the LLM to have a natural language response generated.
Let’s look at the code, and try the app!
Click to view the demo portion of the YouTube video